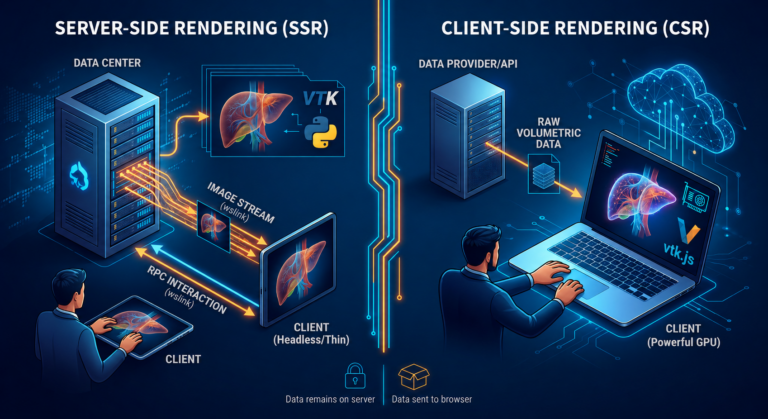
Gestione del ciclo di vita di modelli IA: un'architettura per l'analisi di immagini con PyTorch, MLflow e Optuna
Negli ultimi anni, l’intelligenza artificiale ha rivoluzionato il modo in cui possiamo analizzare e interpretare dati complessi attraverso i sistemi informatici. Queste tecnologie utilizzano modelli parametrizzati in modo automatico a partire dai dati, senza necessità di programmare esplicitamente relazioni e pattern non evidenti o difficili da descrivere e permettendo di migliorarne progressivamente le prestazioni.
Anche in campo medico le applicazioni dell’intelligenza artificiale, in particolare nell’analisi di immagini diagnostiche, stanno trasformando il modo in cui vengono sviluppati strumenti di supporto alle decisioni cliniche. Tuttavia, l’efficacia di questi sistemi non dipende solo dalla qualità dei modelli di deep learning, ma anche dall’infrastruttura tecnica che ne sostiene l’intero ciclo di vita: dall’acquisizione dei dati all’addestramento, dalla gestione degli esperimenti fino alla distribuzione dei risultati.
Lo sviluppo di questi modelli richiede un’infrastruttura in grado di gestire in modo efficiente dati e risorse computazionali. Nel nostro caso, l’obiettivo è supportare progetti di IA basati su immagini medicali fornendo un ambiente integrato e riproducibile che permetta di addestrare reti neurali, archiviare dati e risultati e monitorare l’evoluzione delle prestazioni dei modelli.
Architettura e ambiente di lavoro
L’infrastruttura si basa su un server Linux ad alte prestazioni equipaggiato con GPU dedicate. L’accesso avviene in modo sicuro tramite VPN, consentendo agli sviluppatori di eseguire esperimenti da remoto.
Tutti i processi — dal preprocessing dei dati all’addestramento dei modelli — sono gestiti tramite programmi Python, che utilizzano la libreria PyTorch come framework principale per il deep learning. Le operazioni sono automatizzate all’interno di una pipeline che esegue in sequenza le seguenti fasi:
- Verifica della disponibilità di nuovi dati nel repository.
- Preprocessing e analisi dei dati per renderli adatti al tipo di input atteso dal modello e per escludere eventuali dati non conformi.
- Addestramento e valutazione del modello sulle diverse partizioni del dataset.
- Inferenza sui nuovi campioni e salvataggio dei risultati.
Tracciamento degli esperimenti
Per supportare la tracciabilità e la riproducibilità dei risultati, l’infrastruttura adotta MLflow, una piattaforma open source progettata per gestire l’intero ciclo di vita dei progetti di machine learning.
Tutti i parametri di addestramento, le configurazioni dei modelli e le metriche di performance vengono registrati su MLflow che consente di:
- registrare automaticamente gli esperimenti di addestramento, salvando i parametri utilizzati (iperparametri, configurazioni di rete, versioni dei dati e del codice);
- archiviare i risultati e le metriche di performance (accuratezza, loss, AUC, ecc.);
- visualizzare i risultati in modo interattivo, attraverso grafici e dashboard che facilitano l’analisi comparativa tra diversi modelli o versioni;
- gestire i modelli salvati (model registry), consentendo di versionarli e distribuirli facilmente in ambienti di test o produzione.
Questa integrazione semplifica l’analisi comparativa tra modelli, favorendo un approccio sistematico e riproducibile alla ricerca.
Ottimizzazione automatica degli iperparametri
Per migliorare ulteriormente l’efficienza dei processi di training, è stato integrato Optuna, un framework per l’ottimizzazione automatica degli iperparametri.
Gli iperparametri sono valori di configurazione che influenzano significativamente le prestazioni di un modello di deep learning, come il learning rate, la dimensione del batch, il numero di neuroni negli strati nascosti o i coefficienti dell’algoritmo di ottimizzazione. A differenza dei parametri del modello (pesi e bias), che vengono appresi durante l’addestramento, gli iperparametri devono essere definiti prima dell’inizio del training e la loro scelta può fare la differenza tra un modello mediocre e uno altamente performante.
Tradizionalmente, la ricerca degli iperparametri ottimali avviene tramite metodi manuali o tecniche come la grid search (che testa sistematicamente tutte le combinazioni possibili) o la random search (che campiona combinazioni casuali). Tuttavia, questi approcci risultano estremamente costosi in termini di tempo e risorse computazionali, specialmente quando lo spazio di ricerca è ampio e l’addestramento di ogni configurazione richiede ore o giorni. Optuna risolve questo problema utilizzando algoritmi di ottimizzazione bayesiana e tecniche di pruning automatico. Il framework esplora lo spazio degli iperparametri in modo intelligente e adattivo: analizza i risultati delle configurazioni già testate per suggerire nuove combinazioni promettenti, concentrando le risorse dove è più probabile trovare miglioramenti.
Esempio di addestramento di una convolutional neural network
Quanto appena descritto può essere compreso più facilmente con l’aiuto di un esempio pratico. Abbiamo deciso di allenare una rete neurale che sia in grado di classificare oggetti a partire da immagini. Per questo scopo abbiamo utilizzato il dataset CIFAR-10 composto da 60.000 immagini colorate di dimensioni 32×32 pixels e annotate con 10 diverse classi: ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’.
Prima di eseguire il codice che segue è necessario avviare il tracking server di MLflow lanciando il seguente comando da terminale dentro l’ambiente di sviluppo:
mlflow ui
Servirà in seguito per tracciare l’esperimento.
Come prima cosa importiamo i pacchetti che serviranno per il training eseguito con PyTorch:
import torch
from torch import nn
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, utils
from torchvision.transforms import Compose, ToTensor, Normalize
import torch.optim as optim
import time
A questo punto è possibile scaricare direttamente con PyTorch il dataset CIFAR-10 già suddiviso in train e test set (50.000 e 10.000 immagini rispettivamente). In questa fase le immagini vengono già sottoposte a preprocessing: vengono infatti normalizzate e trasformate per ottenere dei tensori.
# Download and prepare data
transform = Compose([ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = datasets.CIFAR10(
root="./data", train=True, download=True, transform=transform
)
test_set = datasets.CIFAR10(
root="./data", train=False, download=True, transform=transform
)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data\cifar-10-python.tar.gz
100.0%
Extracting ./data\cifar-10-python.tar.gz to ./data
Files already downloaded and verified
Iniziamo ad impostare alcuni parametri di training che ci torneranno utili a breve e visualizziamo le classi presenti nel dataset:
# Set some parameters
batch_size = 4
epochs = 5
classes = train_set.classes
print(classes)
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Visualizziamo anche la composizione dei due dataset:
# Get the number of images per class in the training set
class_count = {}
for _, index in train_set:
label = classes[index]
if label not in class_count:
class_count[label] = 0
class_count[label] += 1
print("Train set:", class_count)
# Get the number of images per class in the training set
class_count_test = {}
for _, index in test_set:
label = classes[index]
if label not in class_count_test:
class_count_test[label] = 0
class_count_test[label] += 1
print("Test set:", class_count_test)
Train set: {'frog': 5000, 'truck': 5000, 'deer': 5000, 'automobile': 5000, 'bird': 5000, 'horse': 5000, 'ship': 5000, 'cat': 5000, 'dog': 5000, 'airplane': 5000}
Test set: {'cat': 1000, 'ship': 1000, 'airplane': 1000, 'frog': 1000, 'automobile': 1000, 'truck': 1000, 'dog': 1000, 'horse': 1000, 'deer': 1000, 'bird': 1000}
Quindi è possibile procedere al caricamento dei dataset sfruttando il DataLoader di PyTorch:
# Get dataloaders
trainloader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
testloader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
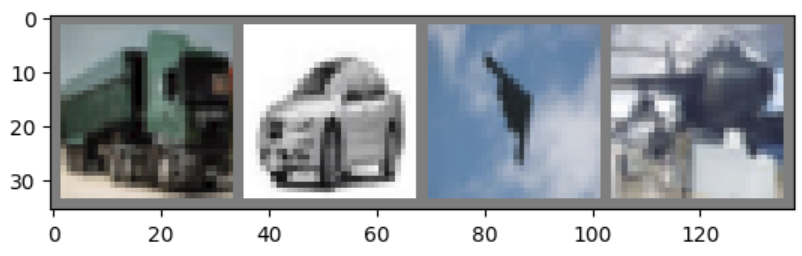
Visualizziamo qualche immagine presa casualmente dal nostro training set:
# Display a batch of data as example
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(utils.make_grid(images))
# print labels
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))
Definiamo il modello che andremo ad addestrare: si tratta di una rete neurale convoluzionale che prende in input immagini a tre canali (RGB):
# Define model
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.conv1(x)))
x = self.pool(nn.functional.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = nn.functional.relu(self.fc1(x))
x = nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Prima di procedere con il training, definiamo un criterio per calcolare la loss function e l’algoritmo di ottimizzazione:
# Optimize model parameters
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
È arrivato il momento di addestrare il modello. Per questo piccolo esempio utilizziamo un batch di dimensione 4 e solo 5 epoche (come già impostato in precedenza), ciò significa che il ciclo di apprendimento verrà iterato sull’intero set di dati per 5 volte:
# Train (use CPU for simplicity)
print("Training model... ")
loss_metric = {}
for epoch in range(epochs):
print("*************** Training epoch ", epoch + 1)
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data # data is a list of [inputs, labels]
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(f"[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}")
loss_metric[str(epoch + 1)] = round((running_loss / 2000), 3)
running_loss = 0.0
print("Finished Training")
Training model...
*************** Training epoch 1
[1, 2000] loss: 2.236
[1, 4000] loss: 1.859
[1, 6000] loss: 1.681
[1, 8000] loss: 1.567
[1, 10000] loss: 1.521
[1, 12000] loss: 1.478
*************** Training epoch 2
[2, 2000] loss: 1.398
[2, 4000] loss: 1.372
[2, 6000] loss: 1.368
[2, 8000] loss: 1.309
[2, 10000] loss: 1.307
[2, 12000] loss: 1.292
*************** Training epoch 3
[3, 2000] loss: 1.221
[3, 4000] loss: 1.221
[3, 6000] loss: 1.211
[3, 8000] loss: 1.185
[3, 10000] loss: 1.184
[3, 12000] loss: 1.188
*************** Training epoch 4
[4, 2000] loss: 1.086
[4, 4000] loss: 1.114
[4, 6000] loss: 1.098
[4, 8000] loss: 1.110
[4, 10000] loss: 1.102
[4, 12000] loss: 1.120
*************** Training epoch 5
[5, 2000] loss: 0.987
[5, 4000] loss: 1.037
[5, 6000] loss: 1.032
[5, 8000] loss: 1.049
[5, 10000] loss: 1.064
[5, 12000] loss: 1.033
Finished Training
Conclusa la fase di addestramento, utilizziamo il test set per testare le capacità predittive del modello. In questa fase useremo l’accuratezza per valutare le performance:
# Test
print("Testing model...")
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the network on the 10000 test images: {100 * correct // total} %")
Testing model...
Accuracy of the network on the 10000 test images: 60 %
Potrebbe essere interessante anche calcolare l’accuratezza per ciascuna classe:
# which class performs best?
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predictions = torch.max(outputs, 1)
# collect the correct predictions for each class
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
# print accuracy for each class
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f"Accuracy for class: {classname:5s} is {accuracy:.1f} %")
Accuracy for class: airplane is 66.8 %
Accuracy for class: automobile is 65.4 %
Accuracy for class: bird is 38.5 %
Accuracy for class: cat is 55.6 %
Accuracy for class: deer is 54.7 %
Accuracy for class: dog is 52.6 %
Accuracy for class: frog is 54.1 %
Accuracy for class: horse is 66.3 %
Accuracy for class: ship is 78.5 %
Accuracy for class: truck is 72.9 %
Infine, salviamo su MLflow i parametri, il modello e le metriche per tenere traccia degli esperimenti eseguiti:
# track the experiment with mlflow
import mlflow
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("/AI-infrastructure-sample")
with mlflow.start_run():
# Log the hyperparameters
params = {"batch_size": batch_size, "number_of_epochs": epochs}
mlflow.log_params(params)
# Log the metric
for key, value in loss_metric.items():
mlflow.log_metric("training_loss", float(value), step=int(key))
mlflow.log_metric("test_accuracy", accuracy)
# Set a tag as experiment description
mlflow.set_tag("Training Info", "Basic model for CIFAR10 data")
# Log the model
mlflow.pytorch.log_model(net, "model")
🏃 View run sassy-hog-743 at: http://localhost:5000/#/experiments/244582946539340454/runs/fb8fa75d03a747dfa86ab343235f29cc
🧪 View experiment at: http://localhost:5000/#/experiments/244582946539340454
Adesso che abbiamo visto come impostare il training e salvare l’esperimento su MLflow, possiamo introdurre Optuna per provare ad ottimizzare gli iperparametri. Per semplicità, nel nostro esempio consideriamo un solo iperparametro: batch_size.
Iniziamo importando Optuna:
import optuna
Scriviamo una funzione obiettivo per Optuna che addestra il modello con diverse dimensioni del batch e restituisce l’accuratezza:
def objective(trial):
# Set the values of the batch size you want to try
batch_size_trial = trial.suggest_categorical('batch_size', [4, 8, 16, 32])
trainloader_trial = DataLoader(train_set, batch_size=batch_size_trial, shuffle=True, num_workers=0)
testloader_trial = DataLoader(test_set, batch_size=batch_size_trial, shuffle=False, num_workers=0)
# Initialize a new model
net_trial = Net()
# Optimize model parameters
criterion_trial = nn.CrossEntropyLoss()
optimizer_trial = optim.SGD(net_trial.parameters(), lr=0.001, momentum=0.9)
# Training
epochs_trial = 3
for epoch in range(epochs_trial):
running_loss = 0.0
for i, data in enumerate(trainloader_trial, 0):
inputs, labels = data
optimizer_trial.zero_grad()
outputs = net_trial(inputs)
loss = criterion_trial(outputs, labels)
loss.backward()
optimizer_trial.step()
running_loss += loss.item()
# Report of the average loss per epoch (for pruning)
avg_loss = running_loss / len(trainloader_trial)
trial.report(avg_loss, epoch)
# Check for pruning
if trial.should_prune():
raise optuna.TrialPruned()
# Test the model
correct = 0
total = 0
with torch.no_grad():
for data in testloader_trial:
images, labels = data
outputs = net_trial(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return accuracy
Creiamo lo studio ed eseguiamo l’ottimizzazione impostando 3 trials:
study = optuna.create_study(
direction='maximize',
study_name='batch_size_optimization',
pruner=optuna.pruners.MedianPruner(n_startup_trials=2, n_warmup_steps=1)
)
study.optimize(
objective,
n_trials=3,
show_progress_bar=True
)
print("\n" + "=" * 50)
print("Optimization completed!")
print("=" * 50)
[I 2025-10-21 15:31:04,879] A new study created in memory with name: batch_size_optimization
[I 2025-10-21 15:33:00,863] Trial 0 finished with value: 56.95 and parameters: {'batch_size': 8}. Best is trial 0 with value: 56.95.
[I 2025-10-21 15:36:43,900] Trial 1 finished with value: 57.72 and parameters: {'batch_size': 4}. Best is trial 1 with value: 57.72.
[I 2025-10-21 15:38:24,708] Trial 2 finished with value: 45.16 and parameters: {'batch_size': 32}. Best is trial 1 with value: 57.72.
==================================================
Optimization completed!
==================================================
Confrontiamo i risultati dei trials per trovare la migliore configurazione che permetta di massimizzare l’accuratezza del modello:
print("\n🏆 BEST CONFIGURATION:")
print(f" Batch Size: {study.best_params['batch_size']}")
print(f" Accuracy: {study.best_value:.2f}%")
print("\n📊 STATISTICS:")
print(f" Number of completed trials: {len(study.trials)}")
print(f" Number of pruned trials: {len([t for t in study.trials if t.state == optuna.trial.TrialState.PRUNED])}")
print("\n📋 ALL TRIALS:")
df = study.trials_dataframe()
print(df[['number', 'value', 'params_batch_size', 'state']].to_string(index=False))
🏆 BEST CONFIGURATION:
Batch Size: 4
Accuracy: 57.72%
📊 STATISTICS:
Number of completed trials: 3
Number of pruned trials: 0
📋 ALL TRIALS:
number value params_batch_size state
0 56.95 8 COMPLETE
1 57.72 4 COMPLETE
2 45.16 32 COMPLETE