Integrazione di SAM3 in un workflow reale basato su DICOM con DICOM Vision
I foundation model come SAM3 (Segment Anything Model 3) sono potenti, ma non diventano utili per definizione.
Nel medical imaging, l’utilità dipende da precisione, controllo e integrazione reale nel flusso di lavoro.
Nel mondo della radiologia e dell’imaging medico, la segmentazione di oggetti è cruciale.
Ma anche notoriamente lunga e complessa.
Prima dei foundation model
Prima dell’arrivo dei foundation model, i workflow di segmentazione si basavano su modelli specifici per ogni compito.
Erano efficaci, ma richiedevano enormi dataset annotati e cicli di iterazione molto lenti:
se volevi segmentare un rene, costruivi un modello per il rene. Se volevi segmentare un tumore, ricominciavi da capo.
Con SAM3 cambia il paradigma
I foundation model “promptabili” come SAM3 rappresentano un cambio di paradigma:
non prevedono un’unica risposta “corretta” basata su training rigido, ma permettono una segmentazione guidata dall’interazione umana.
Ma un modello grezzo non è un prodotto.
Il divario tra generalizzazione e realtà clinica
L’imaging medico impone vincoli che i modelli visivi generalisti non affrontano quasi mai:
Complessità del dato DICOM: gestione di formati medicali nativi, non solo JPEG.
Precisione assoluta: in ambito clinico, la precisione pixel-level non è un’opzione, è una necessità.
Controllo e tracciabilità: il clinico o ricercatore deve restare al centro del processo.
Per questo SAM3 non può essere semplicemente “plug & play”.
Il suo valore emerge solo se integrato con attenzione nel workflow, come assistente alla segmentazione, non come black-box autonoma.
Il nostro approccio: il “Segmentation Assistant”
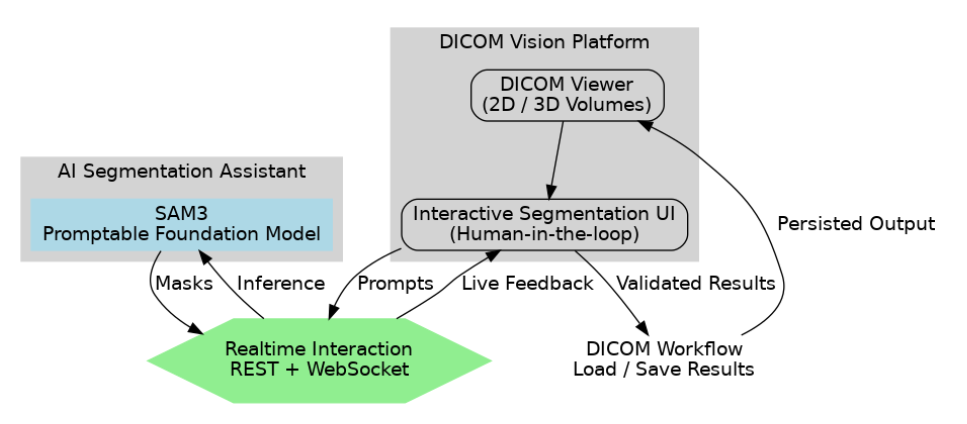
In D/Vision Lab, abbiamo integrato SAM3 come componente on-prem all’interno della piattaforma DICOM Vision.
Non lo abbiamo trattato come un agente autonomo, ma come un layer interattivo all’interno della pipeline esistente.
Ecco come abbiamo strutturato l’integrazione per renderla utile nel mondo reale.
1. Interazione, non automazione
Il flusso inizia dall’esperto.
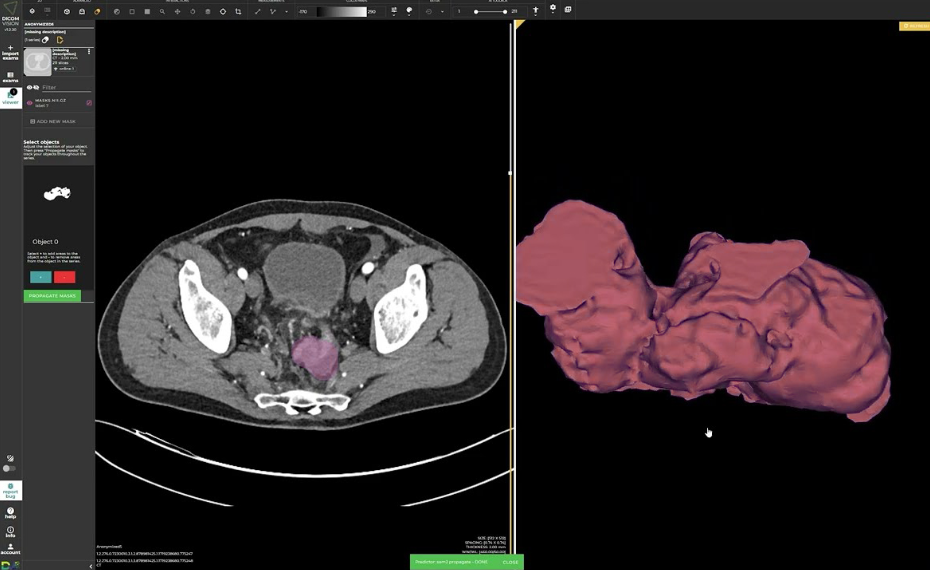
L’interazione parte con prompt puntuali (click), che permettono all’utente di guidare progressivamente il modello verso la struttura anatomica target.
📌 La roadmap prevede anche supporto a bounding box e scribble, ma fin dall’inizio il focus è su interazione incrementale e guidata.
2. Affrontare la sfida del 3D
L’imaging medico è raramente 2D.
Una parte cruciale dell’integrazione è la gestione di volumi 3D completi.
🧠 Come funziona:
L’utente inserisce i prompt su una o più slice, e questi vengono propagati automaticamente sul volume.
In questo modo si ottiene una segmentazione coerente e rapida su centinaia di slice, mantenendo la possibilità di raffinamento manuale dove necessario.
3. Architettura e gestione dei confini
Dal punto di vista architetturale, SAM3 gira come servizio on-prem, in un contenitore Docker, esposto come microservizio dedicato.
Deployment: on-premise, per garantire compliance, latenza minima e protezione dati
Execution: esposto via API REST standard per le richieste di inferenza
Gestione stato: embedding e maschere vengono memorizzati in cache per evitare ricalcoli durante sessioni interattive
Comunicazione:
REST per le richieste standard
WebSocket per feedback a bassa latenza tra DICOM Vision e il modello durante l’interazione
Questo design consente al modello di restare computazionalmente pesante, senza impattare la fluidità dell’esperienza utente.
Il valore strategico: accelerare la ricerca
Anche in questa prima fase, l’integrazione di SAM3 in DICOM Vision ha dimostrato benefici evidenti, soprattutto per i ricercatori in radiologia.
Il loro obiettivo principale è spesso la creazione di ground truth di qualità per addestrare modelli AI futuri.
🎯 Benefici chiave:
Riduzione della frizione: partendo da input minimi, il ricercatore si concentra sulla validazione, non sul disegno manuale pixel per pixel
Cicli più veloci: SAM3 accelera la generazione di dataset, riducendo i tempi tra raccolta, training e valutazione
Conclusione: il modello è l’interfaccia
Dalle prime integrazioni emerge una verità chiave:
I foundation model generano valore quando aumentano il lavoro dell’esperto, non quando tentano di sostituirlo.
In D/Vision Lab, vediamo modelli come SAM3 non come soluzioni end-to-end, ma come interfacce intelligenti.
Nel medical imaging, l’innovazione non viene solo dall’architettura del modello, ma dalla progettazione dell’integrazione, nel rispetto dei vincoli clinici e della collaborazione umana.